
SYNETIC.ai
Synthetic Data for Computer Vision
Synthetic data is changing how computer vision models are being trained. This page will explain synthetic data and how it compares to traditional approaches. After exploring the main methods of creating synthetic data, we’ll help you evaluate and choose the most effective synthetic data source for your project.
Published by SYNETIC AI
June 6, 2025
Download as PDF
Benefits of Using Synthetic Data for Computer Vision
Synthetic data makes high-quality computer vision datasets more accessible to businesses of all sizes. Traditionally, training a model requires manually labeling thousands of real-world images, which is time-consuming and expensive. Synthetic data offers a faster alternative. It generates fully annotated, photorealistic images at scale, allowing teams to build custom datasets tailored to their specific needs without the high cost of manual annotation. Not relying on real-world images or manual annotations leads to more accurate, scalable models and faster adoption of Computer Vision across industries.
There are different types of synthetic data, but in computer vision, it means computer-generated images that come pre-labeled and ready for training. When done right, synthetic data comes with some powerful benefits:
- Faster, cheaper training – You can generate large volumes of labeled data in a fraction of the time it would take to collect and annotate real-world images. There is no crowdsourcing, no bounding boxes by hand, just instant, high-quality data.
- Scalable and customizable – Need 10,000 images of a forklift at night? Or 50 versions of the same object in different weather conditions? Synthetic data lets you create exactly what you need, as much as you need, with complete control over every variable.
- Ultra realistic, high-resolution imagery – Modern rendering tools can produce photorealistic images at resolutions that match or exceed real-world photos. That means sharper details, better edge definitions, and more valuable signals for training advanced models.
- It covers edge cases and rare events – Some scenarios don’t happen often in the real world or are too dangerous or expensive to capture. Synthetic data allows training on crashes, anomalies, equipment failures, or any rare case you want your model to recognize.
- Cleaner, more consistent data – Since labels are generated automatically, you avoid the messiness of human error. You get pixel-perfect annotations every time, with no ambiguity about what’s in the image.
- Proven across real-world applications – Companies already use synthetic data to power object detection, behavior analysis, predictive kinematics, rare behavior identification, and depth/distance estimation. Often with better performance than manually labeled datasets.
Challenges With Using Synthetic Data for Computer Vision
While synthetic data has some significant advantages, it also comes with its own set of challenges that you don’t usually run into with manual labeling or collecting real-world images:
- Realism matters – The model won’t generalize well if the photos don’t look or behave like the real world. This “reality gap” can show up in subtle ways (lighting, shadows, background textures, or object interactions) that break model performance in real environments.
- You need to know your stuff – Unlike collecting real images, synthetic data isn’t just “set it and forget it.” It takes profound domain knowledge to model the right environments, behaviors, object variations, and edge cases. Something that isn’t explicitly included won’t exist in the data.
- It’s not plug-and-play – Generating high-quality synthetic data usually means working with 3D modeling, physics engines, custom scripts, and tuning scene parameters by hand. It can take a lot of time, computing power, and iteration to get it right.
- Quality isn’t guaranteed – Poorly built datasets can be too clean, uniform, or biased. If variation isn’t intentionally built in, the model may overfit to narrow patterns or miss important edge cases.
- Bias can sneak in – Because synthetic data is programmed, it reflects the assumptions of the people and tools building it. If the inputs aren’t diverse or well-designed, the outputs won’t be either, and models can reinforce those blind spots.
- You still need real-world testing – Even the best synthetic data can’t capture everything. You’ll still need to validate and fine-tune models on real images to catch anything your synthetic setup might have missed.
How Synthetic Data for Computer Vision Works
At a high level, synthetic data for computer vision is about generating artificial images with automatic annotations that teams can use to train AI models. Instead of collecting and labeling real-world photos, these images are created using algorithms, 3D models, or simulations. Different methods take different approaches, each with its strengths and tradeoffs.
Here are some of the most common ways to generate synthetic images:
- GANs (Generative Adversarial Networks) – GANs pit two neural networks against each other to create new images that mimic real-world data. They’re great for realism, but can be unpredictable and hard to control.
- VAEs (Variational Autoencoders) – VAEs compress and reconstruct image data, learning the underlying structure to generate new images. They’re more stable than GANs but often produce blurrier results.
- Diffusion Models – These generate images by starting with pure noise and gradually refining it into a realistic picture. They produce high-quality results and are the driving force behind many of today’s cutting-edge generative tools.
- 3D Rendering Engines – Unreal Engine, Blender, and Unity can generate photorealistic scenes using virtual cameras, lighting, and physics. These are ideal for structured environments where complete control is needed.
- Virtual Environments – Fully simulated digital worlds (like driving simulators or factory floors) generate labeled data in bulk. The simulation can customize every object, behavior, and lighting condition.
- Domain Adaptation – This technique takes synthetic images and adjusts them to match real-world characteristics better, helping bridge the “reality gap” between artificial and real data.
Each method makes synthetic data more powerful, flexible, and applicable to real-world vision tasks. In the next section, we’ll dig into the pros, cons, and best use cases for each.
Methods used to generate synthetic data for computer vision
Generative Adversarial Networks (GANs)
What it is
GANs are machine learning models designed to generate new data that looks like a real-world dataset. They’ve become well-known for creating highly realistic, high-resolution images without relying on labeled data.
How it works
A GAN comprises two neural networks—a generator and a discriminator—that train together in competition. The generator tries to create fake images that look real, while the discriminator evaluates whether an image is real or generated. As training progresses, both networks improve: the generator learns to produce more convincing photos, and the discriminator learns to spot subtle flaws until, ideally, the generator is fooling the discriminator with realistic outputs.
Pros
GANs are capable of producing photorealistic, high-resolution images. Once trained, they can generate new samples quickly and don’t require labeled data to get started since they learn by discovering patterns in the data. As a result, they are ideal for boosting dataset variety or filling in gaps where manual collection is limited.
Cons
Training GANs is notoriously tricky. GANs often need large datasets, extensive GPU resources, and careful tuning to avoid issues like mode collapse, where the model generates many identical images. They also offer limited control over the exact features of the output unless advanced conditioning techniques are used. They can unintentionally reinforce bias or low diversity because they replicate patterns from their training data. They may even memorize and reproduce real examples in rare cases, raising security and privacy concerns. Finally, GANs are the backbone of deepfake technology, which introduces ethical and misuse risks depending on the application.
Best suited for
GANs are a strong choice when visual quality is the top priority, and fine-grained control isn’t essential. They’re widely used for data augmentation, style transfer, facial synthesis, and artistic applications. In computer vision, they’re often used to expand datasets or generate visually convincing samples for pretraining or domain adaptation.
Frameworks
These are open-source libraries and model architectures used to build, train, and customize GANs:
- StyleGAN / StyleGAN2 – High-resolution, state-of-the-art GAN architectures developed by NVIDIA
- Pix2Pix / CycleGAN – Popular models for image-to-image translation and domain adaptation
- TensorFlow / PyTorch – Core deep learning frameworks for building custom GANs from scratch
Platforms
These tools provide access to pre-trained models or full synthetic data generation environments, often with GUI-based workflows:
- Runway ML – No-code platform with easy access to trained GANs for experimentation and rapid prototyping
- DataForest – Synthetic data platform offering image generation pipelines, which may include GAN-based tools as part of broader services
Variational Autoencoders (VAEs)
What it is
VAEs are generative models that learn to compress and reconstruct data, creating new samples by exploring a structured latent space. They’re best known for being stable, interpretable, and relatively simple to implement compared to more complex generative methods.
How it works
A VAE learns by encoding input images into a low-dimensional latent representation and decoding that representation back into an image. Instead of memorizing patterns, it learns a smooth probability distribution over the data. This means you can sample new points from the latent space and generate new images resembling the training set. The model balances two goals: accurately reconstructing the original image and keeping the latent space well-behaved and continuous.
Pros
VAEs are easier to train and more stable than GANs, making them accessible to teams without deep ML expertise. Their structured latent space makes generating variations and interpolating between examples easy. They don’t recreate training data directly, which can reduce privacy concerns. The architecture is relatively lightweight and adaptable, making VAEs a good entry point for generative modeling.
Cons
The most significant tradeoff is image quality. VAEs often produce blurrier, lower-resolution images with less detail than GANs or diffusion models. They also require tuning to balance reconstruction accuracy with latent space regularity. Like other generative methods, they can still carry forward biases or a lack of diversity from the training data. And because they generalize and smooth features, fine details can get lost.
Best suited for
VAEs are great for exploring variations, understanding latent features, or generating data with control and stability. They are not suited for projects requiring perfect realism. They’re often used in anomaly detection, image denoising, exploratory data generation, or as building blocks in complex systems. In computer vision, they’re useful when approximate, diverse samples are enough, or when interpretability is a priority.
Frameworks
- NVAE – NVIDIA’s high-resolution VAE architecture, designed for better image quality at scale
- PyTorch / TensorFlow – Flexible environments for building custom or experimental VAEs
- Keras – Easy-to-use interface for getting basic VAEs up and running
- scVI / VAE-Sim – Specialized implementations used in science and research, sometimes adapted for vision tasks
Platforms
- Weights & Biases / Comet – Great for visualizing latent space behavior and monitoring VAE training
- Hugging Face Spaces – Hosts interactive demos for VAE models, helpful for testing outputs or showcasing prototypes
- DataForest – May use VAE components as part of broader pipelines for synthetic data generation in specific domains.
Diffusion Models
What it is
Diffusion models are generative models that produce some of the highest-quality images available today. They’re at the core of tools like DALL·E 2, Imagen, and Stable Diffusion and are known for their photorealism, flexibility, and diversity of output.
How it works
A diffusion model learns to reverse a process of gradually adding noise to an image. During training, it observes how clean images degrade into static. Once trained, it generates new images by starting with pure noise and denoising it step by step, essentially running the process in reverse. Each step adds detail, structure, and realism until a complete image emerges.
Pros
Diffusion models produce incredibly high-quality, realistic images that are often more diverse and detailed than GANs. They’re more stable during training, less prone to mode collapse, and can generate various outputs. Depending on the configuration, they also work flexibly across different input types, like text prompts, sketches, or other images.
Cons
The tradeoff is speed and compute. Diffusion models are much slower at generating images than GANs or VAEs, sometimes requiring hundreds of steps per output. They demand significant GPU resources, especially for training. While more stable, they can still be challenging to implement and fine-tune. Finally, focusing on texture and pattern can sometimes introduce small, nonsensical, or overly stylized details that don’t make sense in context.
Best suited for
Diffusion models are ideal when image quality is the top priority and compute resources are available. They’re widely used in creative tools, content generation, and synthetic data pipelines that need lifelike visuals. In computer vision, they’re gaining traction for domain adaptation, rare event generation, and augmenting datasets with highly diverse, detailed images.
Frameworks
- Stable Diffusion – Open-source, customizable diffusion model with wide adoption
- DDPM / DDIM – Foundational model architectures that form the basis of many diffusion systems
- OpenAI Diffusion – Underlying engine behind DALL·E 2, though not open-source
- Hugging Face Diffusers – Toolkit for loading, fine-tuning, and deploying state-of-the-art diffusion models
Platforms
- Replicate / Runway ML – Offer hosted diffusion models with low-code or no-code interfaces.
- Hugging Face Spaces – Public demos and notebooks for diffusion-based experiments
- DataForest – May include diffusion techniques in its synthetic generation pipeline for advanced visual realism.
3D Rendering Engines
What it is
3D rendering engines create synthetic images by simulating real-world environments using virtual objects, lighting, cameras, and Physically Based Rendering (PBR). These tools let you build fully controlled scenes from scratch, allowing for precise image generation and automatic labeling that are ideal for computer vision datasets.
How it works
You construct a virtual environment using 3D models, place objects, adjust lighting, and define camera angles and movement. The engine renders photorealistic images by simulating how light interacts with surfaces. Since you control the entire scene, every object, label, and relationship can be tracked automatically and produce pre-annotated images consistently across large datasets.
Pros
3D rendering engines allow you to generate precisely the data you need, down to the angle, lighting, and object variation. All images come pre-annotated, which saves time and avoids human labeling errors. You can scale up indefinitely, simulate dangerous or rare scenarios safely, and bypass privacy concerns entirely. These methods are often far more cost-effective than real-world data collection in the long run, and the visual fidelity can be stunning when built with the right tools.
Cons
The most significant barrier is the upfront cost and effort. You must source or create 3D models, design scenes, and sometimes script behaviors or physics interactions. It’s also possible to over-engineer the visuals, where the data can become “too perfect” and lack the accidental variation found in real-world imagery. If you don’t explicitly model something (like a specific texture, defect, or lighting anomaly), it simply won’t appear. The process is computationally expensive, and all edge cases must be pre-defined in order to be created
Best suited for
Rendering engines are ideal for high-precision use cases like robotics, autonomous vehicles, industrial safety, and behavior modeling: any scenario where real-world data is challenging to get or replicate. They’re also perfect for simulating rare or hazardous conditions where real image capture isn’t practical or safe.
Frameworks
- Unreal Engine – AAA-quality visuals with Python scripting and strong CV integration
- Unity – A flexible, developer-friendly engine with large asset libraries and simulator plugins
- Blender – Open-source 3D suite with automation options via BlenderProc or custom Python scripts
- NVIDIA Omniverse – High-end simulation platform with complete pipeline control and collaborative 3D scene-building
Platforms
- Omniverse ACE – Used for simulating avatars and facial/body tracking with ultra-realistic behaviors
- AirSim – Microsoft’s open-source platform for aerial and autonomous vehicle simulations
- Parallel Domain – Enterprise platform offering custom 3D synthetic data pipelines for AV, robotics, and infrastructure
- DataForest – May offer integrated 3D rendering within its synthetic data services for specialized applications.
Virtual Environments & Simulation Software
What it is
Virtual environments are fully simulated digital worlds that mimic real-world spaces like city streets, warehouses, fields, or factory floors. They simulate how agents like vehicles, robots, or people behave in different conditions and generate synthetic data across a wide range of dynamic scenarios.
How it works
Simulation software creates interactive 3D environments where objects and agents move, respond to physics, and interact with their surroundings. Synthetic data is generated by placing cameras or sensors inside the simulation, just like capturing real-world footage. You can control the time of day, object density, weather, physics interactions, and more. Most systems output fully annotated data, including bounding boxes, segmentation maps, trajectories, depth, and even multimodal sensor streams like LiDAR or radar.
Pros
Simulated environments offer safe, repeatable testing for scenarios too dangerous or rare to capture in the real world. You can simulate motion, behavior, and interaction with high realism and easily recreate scenarios for debugging or retraining. These environments are scalable, flexible, far more cost-effective than physical testing, and everything is automatically labeled.
Cons
Building a realistic simulation is complex. You’ll need high-quality assets, physics engines, and scripting logic to produce meaningful outputs. If the simulation isn’t accurate or varied enough, it can create a reality gap, where the model performs well in the virtual world but fails to generalize. Simulations also require significant computing resources, especially on a large scale or with multimodal data.
Best suited for
Simulation software is ideal for training and testing autonomous vehicles, drones, robotics systems, and other agents interacting with the physical world. It’s especially powerful for safety validation, edge-case generation, and pre-deployment testing in controlled virtual environments.
Frameworks
- CARLA – Open-source simulator for autonomous driving
- LGSVL / SVL Simulator – Scalable simulator for autonomous systems
- Gazebo – Robotics simulator used for SLAM, path planning, and perception
- Unity Simulation Pro – Cloud-enabled simulation for large-scale CV workflows
- Airsim – Drone and vehicle simulator with photorealistic rendering and physics
- FlightGoggles – High-speed drone simulation platform for vision-based navigation
Platforms
- Parallel Domain – Commercial platform for generating synthetic data in simulated urban and industrial environments
- Foretellix – Scenario-based simulation and safety validation for autonomous vehicles
- NVIDIA Isaac Sim (on Omniverse) – Robot simulation platform with physics, perception, and training loops
- DataForest – May integrate simulation capabilities tailored to specific verticals like agriculture or logistics.
Many of these simulation platforms also rely on physically based rendering engines to generate realistic visuals and object interactions. Without real-world physics models enhancing the data, images would look flat and be unusable for training.
Domain Adaptation
What it is
Domain adaptation is the process of adjusting synthetic data to match real-world data better, visually or statistically. This technique enables models trained in simulation to perform well in the real world. It doesn’t generate new data from scratch but fine-tunes how synthetic images look and behave to reduce the “reality gap.”
How it works
Even the best synthetic data often looks too clean or too perfect. Domain adaptation bridges this gap by transforming synthetic images or their internal representations to resemble real-world conditions. This can involve style transfer (like turning rendered scenes into photorealistic ones), feature alignment, or noise and artifact injection. Some techniques operate at the image level (e.g., with GANs), while others directly adapt the model’s internal features.
Pros
Domain adaptation can be easier and faster than making synthetic images perfect on the first try. It enhances realism without needing manual annotation or reshooting data. You don’t have to tweak your simulator for every variation because adaptation can fill visual gaps. It’s beneficial when you have a lot of synthetic data and only a small amount of real data.
Cons
There are tradeoffs. Adaptation can break annotations if it alters objects too much, like shifting pixel edges or warping shapes. It also adds complexity to training and often requires real-world images with enough variation to work correctly. It introduces additional compute costs and, depending on the method, may reduce diversity by blending styles. And as physically based rendering and simulation tools get more accurate, the need for adaptation is declining.
Best suited for
Domain adaptation is best used when you already have a substantial synthetic dataset and want to improve real-world model performance without starting over. It’s common in robotics, AV, inspection systems, and medical imaging, especially when real data is difficult to collect or label.
Frameworks
- CycleGAN / CUT – Unpaired image-to-image translation for style transfer
- AdaptSegNet / DANN – Feature-level adaptation for segmentation and classification
- SimGAN – Refines synthetic images with GANs while preserving structure and labels
- Sim2Real Toolkits – Tools for robotics and autonomous training environments
- PyTorch / TensorFlow – For building custom domain adaptation models
Platforms
- Parallel Domain – Offers domain-adapted synthetic datasets tuned for specific environments.
- DataForest – May include domain adaptation as part of dataset delivery and tuning.
- Hugging Face – Hosts open-source adaptation models, especially in the GAN and CV space.
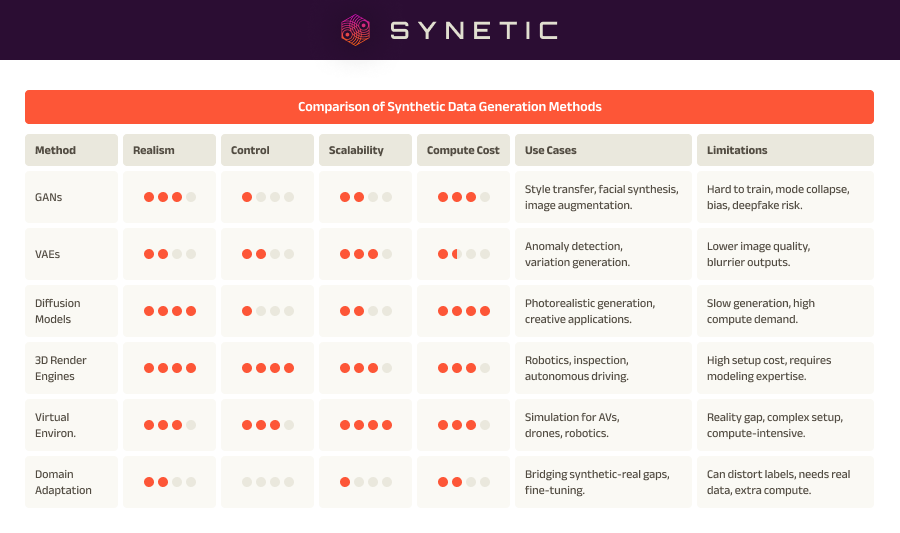
Comparing Synthetic Data Methods
Each method for generating or refining synthetic data has its strengths. GANs, VAEs, and diffusion models are fast and flexible for image generation, though they vary in control and realism. 3D rendering engines and virtual environments offer precision and scalability, especially for structured scenes and behavior simulation. Domain adaptation acts as a bridge, helping synthetic data perform better in the real world. The right choice often depends on your use case, your team’s expertise, and how much realism or variation your model needs.
Comparison of Synthetic Data Generation Methods
Examples of Synthetic Data for Computer Vision
1. Synscapes
Photorealistic synthetic dataset for semantic segmentation and object detection.
Focus: Autonomous driving
https://www.synscapes.com/
2. Virtual KITTI 2
Synthetic clone of the KITTI dataset built in Unity.
Focus: Object detection, tracking, scene flow
https://europe.naverlabs.com/research/computer-vision/proxy-virtual-worlds/
3. CARLA (with Dataset Outputs)
Open-source simulator that generates synthetic data for autonomous vehicles.
Focus: RGB, LiDAR, control signals
https://carla.org/
4. AirSim
Microsoft’s simulator for drones and ground vehicles, with photorealistic scenes.
Focus: Aerial robotics, AV simulation
https://github.com/microsoft/AirSim
5. BlenderProc
Pipeline for procedural scene generation in Blender with automatic annotations.
Focus: Object detection, segmentation, depth
https://github.com/DLR-RM/BlenderProc
6. Falling Things (FAT)
Synthetic dataset for 6D pose estimation using YCB objects.
Focus: Object pose, occlusion, clutter
https://research.nvidia.com/publication/2018-05_falling-things
7. Synthehicle
Realistic and stylized images of vehicles for detection and localization.
Focus: Small and large vehicle detection
https://github.com/valeoai/Synthehicle
8. SceneNet RGB-D
Massive synthetic indoor dataset for depth prediction and segmentation.
Focus: Robotics, indoor CV
https://robotvault.bitbucket.io/scenenet-rgbd.html
9. Hugging Face Datasets & Model Hub
Open-source models and datasets for image generation, style transfer, and domain adaptation.
Focus: Generative models, GANs, diffusion, Sim2Real tools
https://huggingface.co/
Case Studies: Proving the Value of Physically Based Synthetic Data in Computer Vision
Physically based 3D synthetic data is already transforming agriculture. Ag-Tech companies use simulated environments and photorealistic rendering to train high-performance computer vision models from crop analysis to livestock health. The following examples show how this approach enables faster development, better accuracy, and real-world impact across the farm.
Spudbud helps potato growers solve a longstanding problem: not knowing exactly what’s in the cellar. Traditionally, potatoes are weighed as trucks unload, giving growers a rough estimate of total volume but no detail on size distribution or quality. That makes it hard to commit to sales contracts confidently. Spudbud uses a camera mounted on the loading apparatus and physically based synthetic data to train a real-time vision model that counts and sizes each potato. By simulating thousands of lighting conditions, pile shapes, and potato variations in a virtual 3D environment, Spudbud generates the training data needed without ever stepping foot in a cellar. The result is precise inventory data so growers and processors can make contracts that match what they have. No overselling. No underdelivering.

Horsewise addresses a critical challenge in equine care: catching health issues like colic or cribbing before they become dangerous or fatal. These conditions develop quietly and escalate quickly, leading to expensive treatment or preventable loss. Horsewise installs cameras in individual stalls and uses a computer vision model trained on physically based synthetic data to recognize early signs of distress or abnormal behavior. By simulating a wide range of horse movements, lighting conditions, and stall layouts in 3D, Horsewise builds robust training datasets without the need to capture actual incidents. The system detects unusual patterns in real time and instantly alerts barn managers, owners, or vets, allowing them to intervene early and protect the horse’s health.

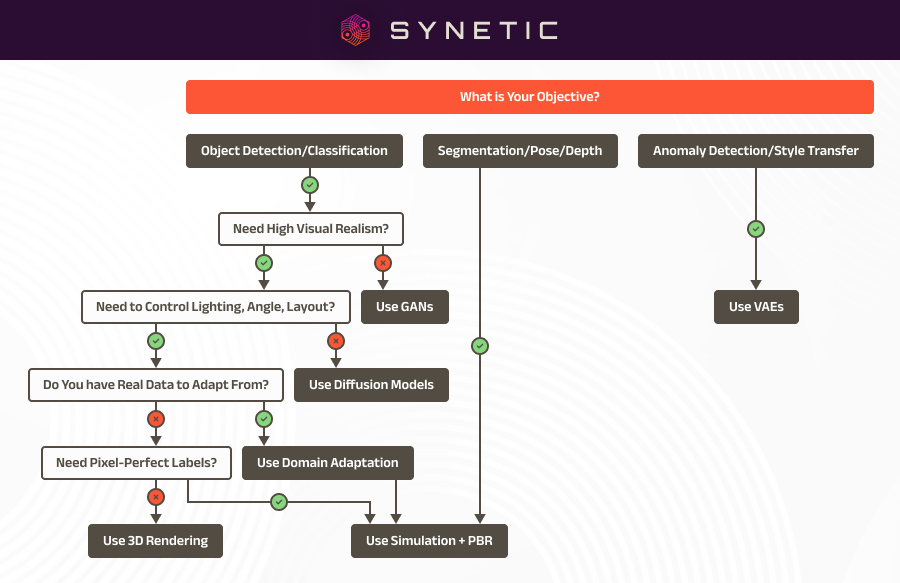
How to pick the correct synthetic data for your computer vision project
How to pick the correct synthetic data for your computer vision project
Not all synthetic data is created equal, and not every project needs the same approach. The correct synthetic data depends on your use case, the level of realism required, the type of model you’re training, and what kind of variability or control your task demands. Here are a few key factors to consider:
- What are you trying to recognize?
For simple object detection, faster generative methods like GANs or basic rendering may work. You’ll likely need physically based simulation and high-resolution rendering for fine-grained detail (like surface defects or motion behavior). - How much variation do you need?
If your model needs to generalize across environments, lighting, or angles, you’ll need synthetic data that can systematically generate those conditions, typically through simulation and PBR pipelines. - Do you have real data to supplement or adapt from?
If you already have some real images, domain adaptation can help make synthetic data more effective. If you don’t, you may need more realism and coverage from the start. - Do you need pixel-perfect labels?
Tasks like segmentation, depth estimation, and pose tracking benefit most from simulation-based synthetic data, where every label is generated automatically and accurately. - What’s your budget and timeline?
Simple GANs or low-fidelity rendering may be enough for early experimentation. However, investing in structured, physically based synthetic data can save time and reduce costs for production-grade models. - Do you control the environment?
Synthetic data can be highly effective in tightly controlled environments (like manufacturing) with limited variation. Broader variation and simulation are critical in open-world or unpredictable scenarios (like agriculture or AV).
Replace Real-World Bottlenecks with Scalable, High-Fidelity Synthetic Data
At Synetic, we generate ultra-realistic synthetic data that is purpose-built for computer vision. Using advanced 3D modeling, physically based rendering, and high-variance simulations, we create datasets that reflect real-world complexity without the slowdowns of manual data collection. Every dataset is customized to your use case, ensuring diversity, precision, and label-perfect accuracy from the start. No need to manage compute infrastructure, we handle the heavy lifting so you can focus on building great models.
Why Choose Synetic as your 3D data provider?
At Synetic, we specialize in providing the highest quality synthetic images tailored to the specific needs of your computer vision projects. Here’s why we stand out:
1. Expertise in Custom Data Generation
We combine cutting-edge 3D modeling, advanced simulations, and physically based data generation to create ultra-realistic datasets. Unlike off-the-shelf solutions, we provide customized datasets that reflect the real-world complexity of your application.
2. Scalable Solutions
We understand the challenges of working with large datasets. Our scalable synthetic data solutions enable you to quickly generate the data needed to train models without the cost and time associated with manual data collection.
3. High Accuracy and Realism
Our focus on creating highly accurate and realistic data ensures that your Computer Vision models can perform at their best. We go beyond simple image generation, incorporating detailed physics simulations and environmental variables to match real-world conditions.
4. Cost-Effective
With synthetic data, you don’t have to rely on expensive real-world data collection. We help reduce costs while ensuring your data is relevant and precisely matched to your use case.
5. Industry-Leading Technology
We stay ahead of the curve using the latest advances in AI, computer vision, and data simulation technologies. Our data solutions are built on years of experience and continual innovation, ensuring you get the best possible data for your models.
6. Accessible to All Businesses
By making high-quality, custom synthetic datasets more accessible, we enable businesses of all sizes to leverage computer vision technology. Whether you’re a startup or an established enterprise, we empower you to create powerful, scalable Computer Vision models without the traditional barriers to entry.
7. Specialized Use Cases
Our data enables various specialized applications, including behavior analysis, predictive kinematics, rare behavior identification, weight, depth, and distance estimates. Whether you’re focusing on complex human behavior or advanced measurements, we provide the data needed for accurate model training.
Ready to explore synthetic data from Synetic for your Computer Vision?
Whether building your first computer vision model or scaling up an entire AI pipeline, the right data makes all the difference. Synetic delivers high-fidelity synthetic datasets that help you move faster, train better, and unlock performance you can’t get with real-world data alone.
Let’s build something more imaginative—together.
Contact Us Today to discuss your needs and start building your custom synthetic dataset!