
STEP 01
Generate the data
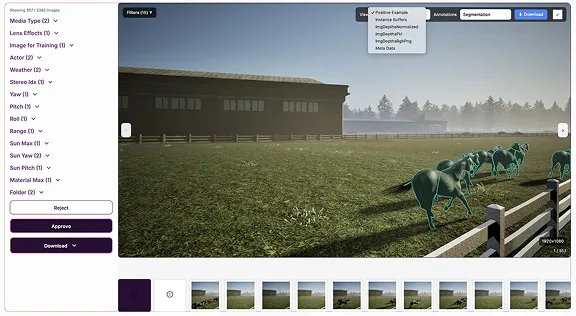
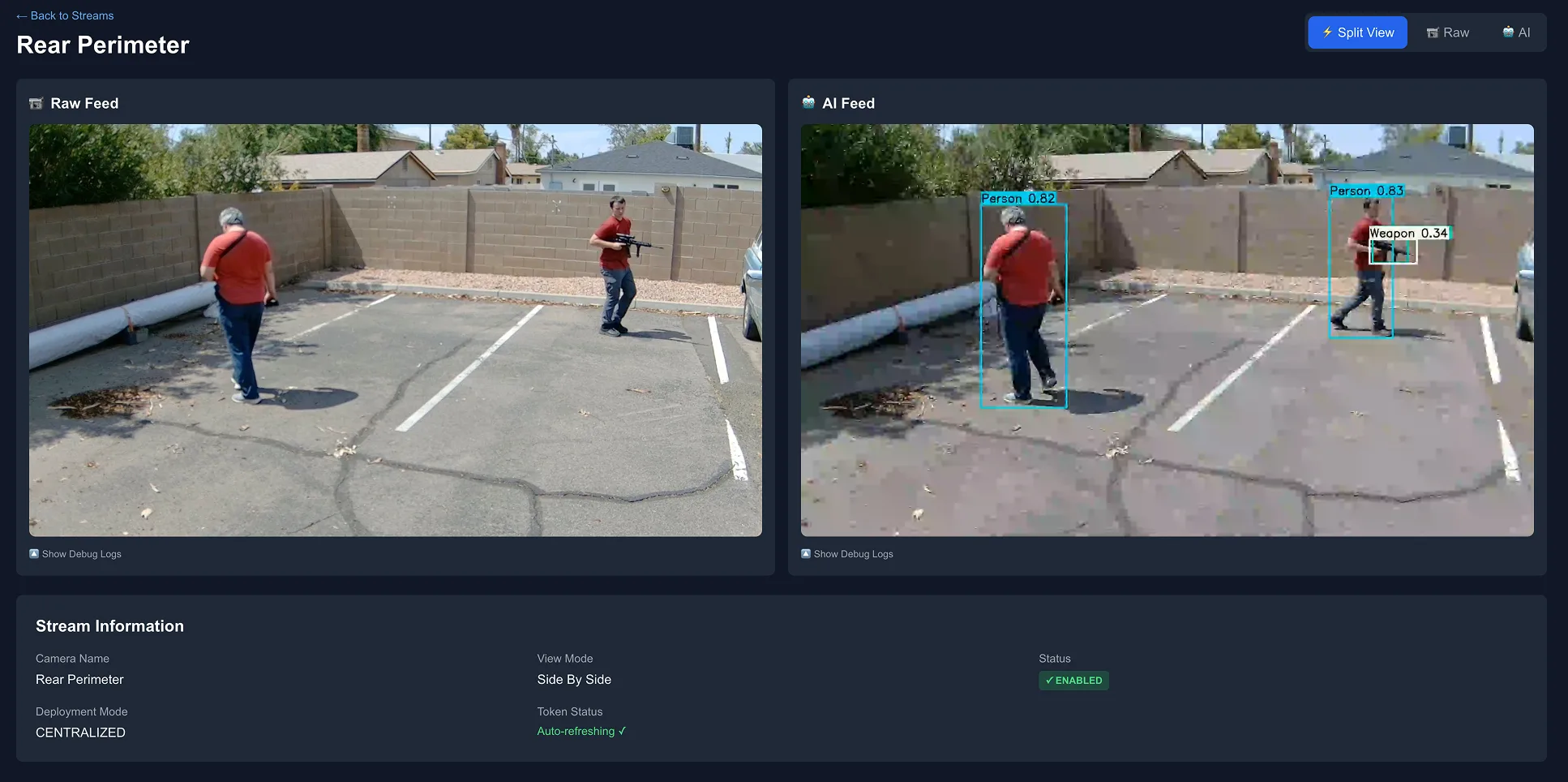
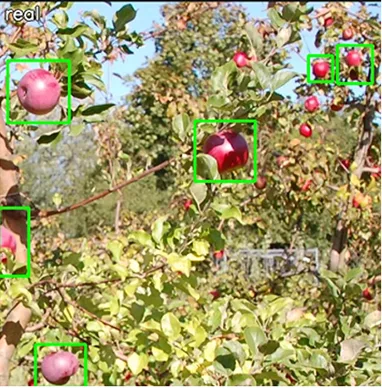
Control every parameter: lighting, weather, camera angle, actors, occlusion. Generate unlimited variations.
- ›Parametric scene controls
- ›Unlimited scenario variations
- ›No data-collection slog