
SYNETIC.ai
Learn about Computer Vision
Synthetic data is revolutionizing computer vision. Synetic.ai provides an automated platform for generating training datasets that are photorealistic, annotated, and customizable.
Published by SYNETIC AI
June 6, 2025
Download as PDF
How Computer Vision Works
Computer vision is the process of extracting meaning from images using statistical patterns in pixel data. A digital image is simply a grid of color values. By themselves, these values mean nothing.
By looking at millions of examples, models learn how likely a certain arrangement of pixels is to match an object. This could be a dog, a traffic sign, or a forklift. However, a trained model can find patterns. It can detect edges, textures, gradients, and spatial arrangements. These patterns help classify objects in the scene.

By looking at millions of examples, models learn how likely a certain arrangement of pixels is to match an object. This could be a dog, a traffic sign, or a forklift. They build a visual grammar over time using layers of convolution and feature extraction.
Advanced models go further by studying how patterns evolve across video frames or different viewpoints. If the same shape shows up often, even with different lighting, angles, or blocks, the model connects it to the same object. This is how models gain an understanding of identity, motion, and continuity.
In essence, computer vision is not about “seeing” like a human. It’s about calculating probabilities based on visual patterns. The more varied situations a model experiences, the better it becomes at making accurate predictions. This includes different lighting, angles, and backgrounds.
Why Do We Need So Many Images for Computer Vision Training?
One of the main challenges in computer vision is how sensitive models are to small changes in an image. These changes can include lighting, angle, or rotation, which can completely alter the pixel values.
AI models do not recognize objects like humans do. They learn by finding patterns in millions of pixel arrangements. If an object appears in a new pose or place, the model needs to have seen many different examples to recognize it well.

This difference is easy for a human to ignore. However, to a model, it looks like the dog has become a new object. Robust computer vision models need large and diverse datasets. This is important not just to memorize, but to understand real-world differences.
The wider the range of angles, lighting, backgrounds, and partial obstructions a model sees during training, the better it can perform in real use. Without this variation, models quickly become brittle, failing when presented with anything outside their narrow training experience.
Importance of a Robust and Comprehensive Synthetic Training Set
The performance of a computer vision model is only as strong as the data it learns from. A strong training set must consider real-world differences.
These include variations in object size, shape, lighting, camera angle, background, and partial occlusion. If a dataset lacks these variations, the model may struggle to identify even basic objects. This can happen in new situations.
As a use case we will use a warehouse detection system. If it only sees forklifts in bright light, it may not recognize them in dim light or from odd angles.
This phenomenon, called poor generalization, occurs when a model overfits to a narrow training distribution. A complete dataset helps the model understand better. This means it can find patterns and objects in many new situations. We call this “generalization”.
This is why modern datasets often contain tens or hundreds of thousands of images per category. The more complete the dataset, the more real-world-ready the model becomes.

How Traditional Computer Vision Datasets Are Built
Most computer vision models are still trained using datasets built from real-world photographs. People often take these images from the internet or capture them by hand. People then label them—sometimes with all the enthusiasm of a Monday morning. This process is slow, costly, and can be inconsistent.
Making a dataset of 10,000 labeled images can take many hours and cost a lot of money. This is especially true when you need precise details for tasks like segmentation or keypoint annotation. Many teams outsource this work to large annotation services or distributed gig workers, introducing variability in label quality and interpretation (and sometimes, creative interpretations of what a forklift actually is).
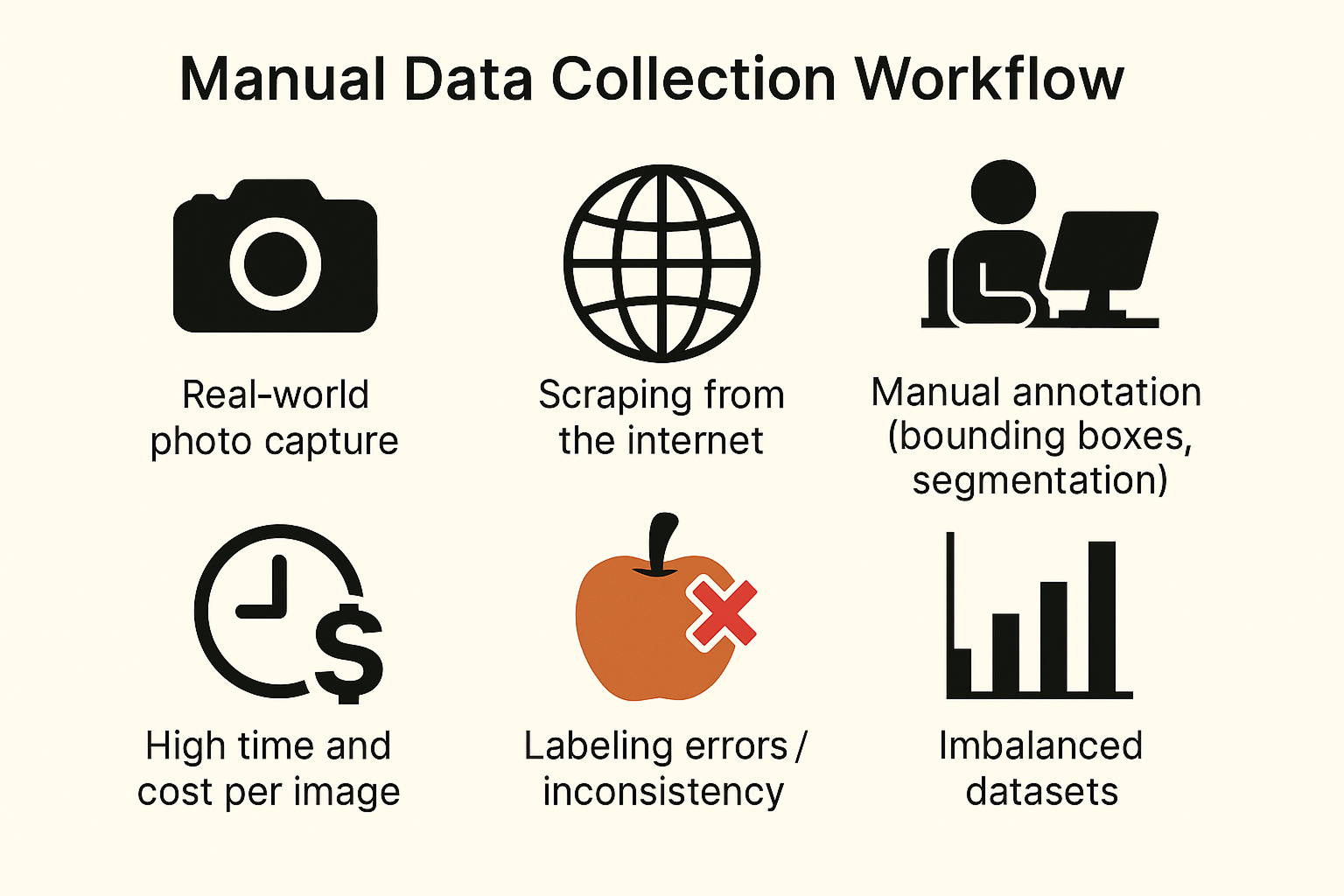
Also known as: the intern’s least favorite part of the job (and the primary reason for so much coffee).
Traditional datasets also suffer from imbalance. Some object types, lighting conditions, or camera angles often dominate. However, important edge cases may be completely missing. This skews model behavior and limits generalization—no matter how many interns you have on hand.
These challenges have lasted for more than ten years. They reduce the speed and reliability of training and using new vision systems. As tasks become more specialized, the need for manual collection and labeling shows its limits.
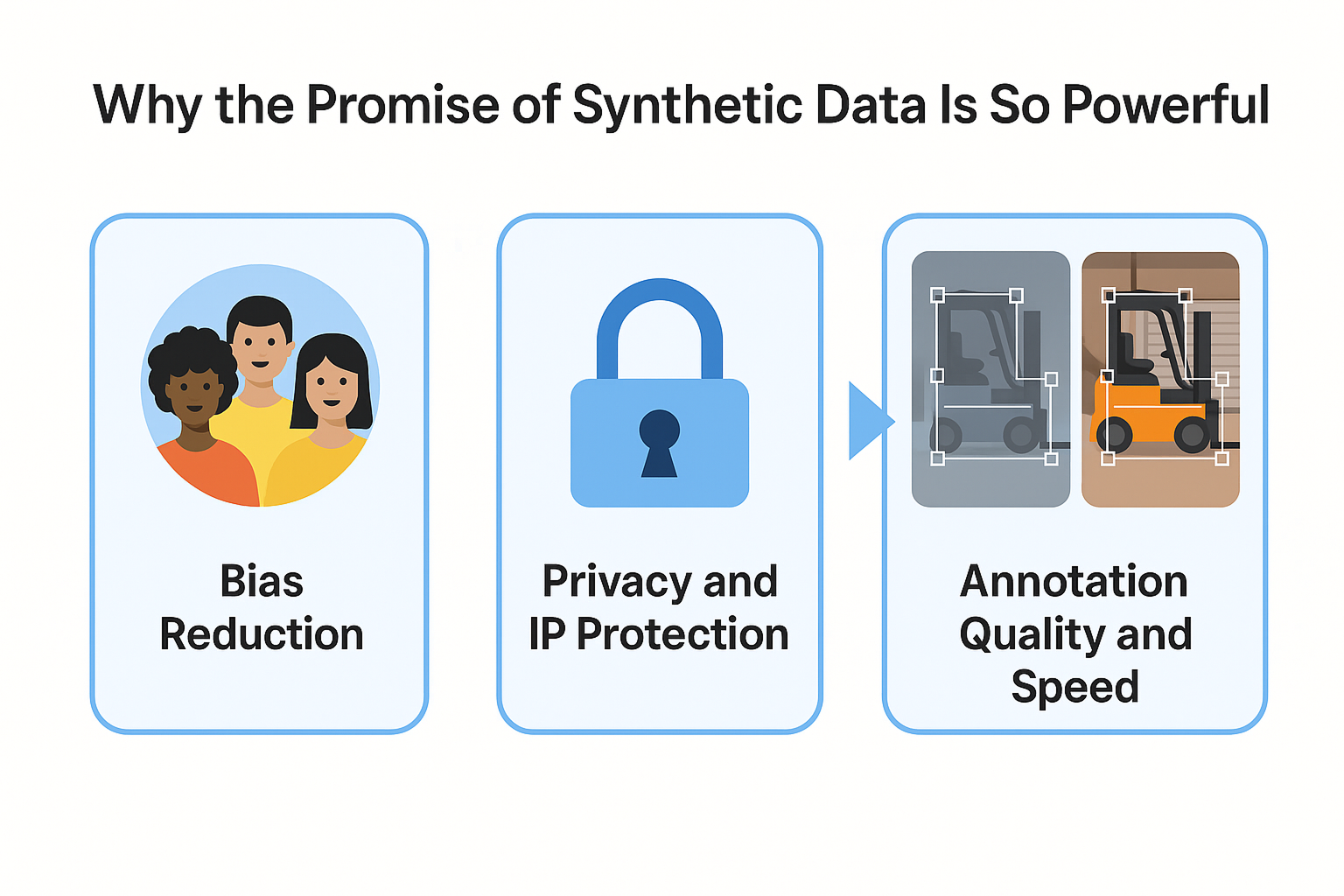
Why the Promise of Synthetic Data for Computer Vision Is So Powerful
Synthetic data is transforming how computer vision models are trained. Teams can now create perfectly labeled data at scale. They do this by using simulation and rendering instead of collecting and labeling real-world images by hand. This unlocks faster iteration, lower costs, and more precise control.
Need 50,000 foggy night-time images of a forklift from 30° overhead? Done.
Synthetic data allows us to create rare situations and edge cases. These cases would be too expensive or hard to capture by hand. You decide what appears, which conditions vary, and which annotations you include.
This is not just about speed: it’s about control and consistency. Every pixel, label, and variation is intentional. Want a balanced dataset with 20% snow, 15% shadows, and 5% partial occlusions? Just specify it.
As models become more specialized, and environments get more complex, synthetic data is important. It helps create the variety needed for good performance.
It allows for complete scene understanding, stress testing, and simulating conditions that are not real yet. This all happens before using any camera.
Also privacy-compliant and IP-safe. Synthetic data is created, not collected. This means there is no risk of exposing personal data, breaking licenses, or facing GDPR issues. You own the data and its usage rights, down to the label.
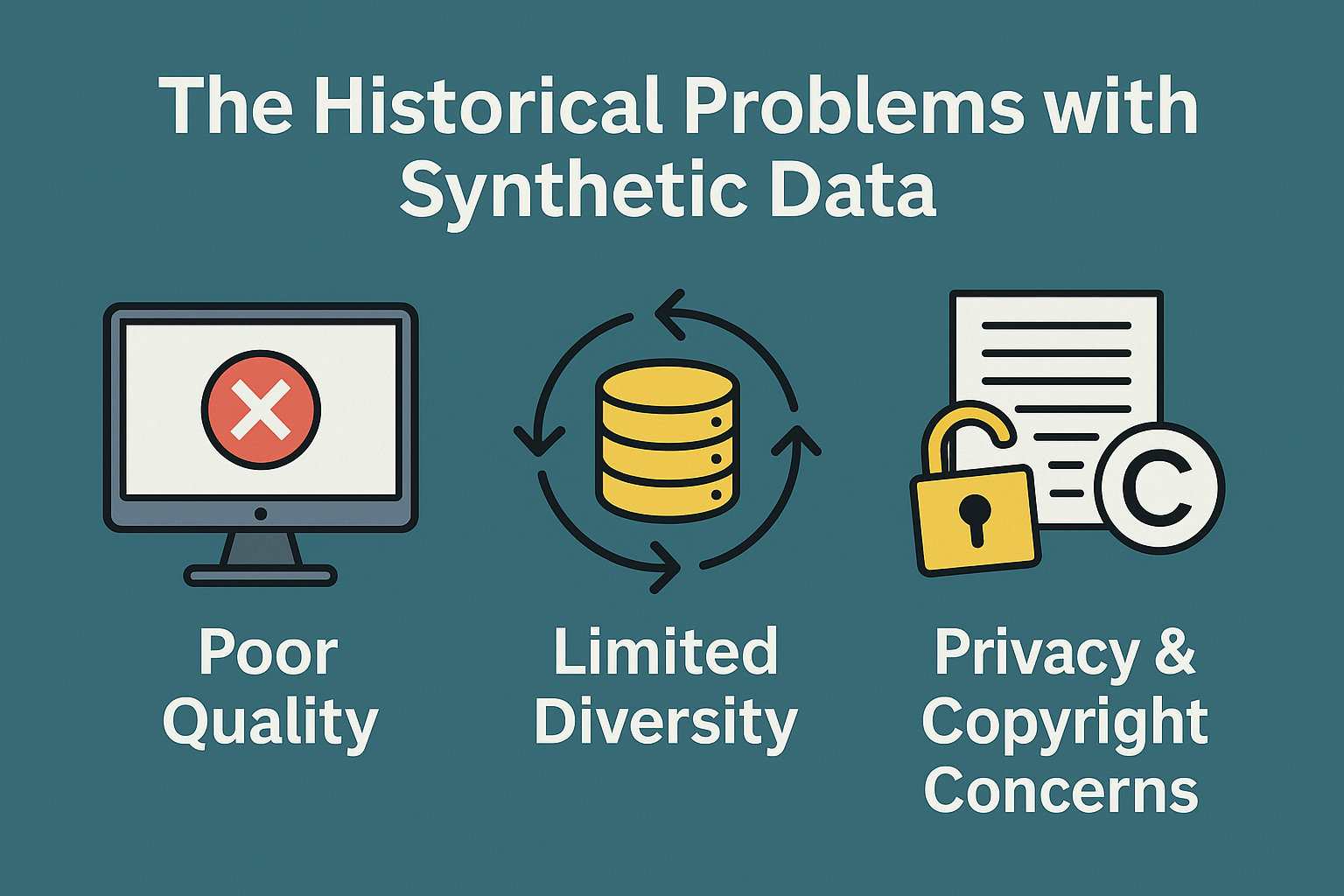
The Historical Problems with Synthetic Data for Computer Vision
The concept of synthetic data for computer vision is not new, but early attempts faced significant hurdles. Early synthetic datasets lacked realism. Objects looked plastic, lighting was off, and backgrounds felt fake, making them hard to use for real-world training. As a result, models trained on these early synthetic images struggled to perform well when exposed to real-world data.
A critical issue was the so-called “reality gap.” Models could detect objects in simulated environments, but their ability to generalize to real-world conditions was poor. This gap stemmed from limited visual diversity, unrealistic textures, and a lack of environmental variation. Early synthetic datasets rarely included the full spectrum of lighting, weather, occlusion, or camera perspectives found in real scenes.
Another historical problem was the lack of control and flexibility in data generation. Many early synthetic data tools produced static scenes or required extensive manual setup for each scenario. Teams struggled to introduce rare edge cases, simulate sensor noise, or create balanced datasets that reflected deployment environments. This limited the usefulness of synthetic data for robust model training.
Because of these limitations, engineers and researchers remained skeptical. Synthetic data was seen as a shortcut that couldn’t deliver the reliability or generalization of real-world photographs. For years, the field relied on manual data collection and annotation, despite the associated costs and bottlenecks.
How Synetic AI Solves Synthetic Data Challenges for Computer Vision
Synetic AI eliminates the challenges of legacy synthetic data by combining advanced simulation, procedural generation, and photorealistic rendering. We begin with detailed, physically accurate 3D models designed to reflect real-world objects, environments, and behaviors.
We animate these models to reflect natural movement, operational states, and rare edge-case behaviors. Our procedural engine then varies scene elements—including lighting, backgrounds, camera angles, occlusion, weather, and sensor effects—at scale. This generates massive, diverse datasets that mirror the complexity of real-world deployment.
Synetic AI leverages state-of-the-art rendering technology to deliver lifelike images with realistic shading, reflections, material textures, and environmental effects. Every frame is produced at high resolution, ensuring models learn from deployment-grade visuals.
Each image is automatically annotated with pixel-perfect precision. We support bounding boxes, instance and semantic segmentation, depth maps, keypoints, and behavioral metadata. This removes the need for manual labeling and ensures consistency in the dataset.
By tightly integrating handcrafted assets with procedural variability and automated annotation, Synetic AI closes the “reality gap.” Models trained on our synthetic data work well in real-world situations. This includes low light, occlusion, motion blur, and unexpected events.
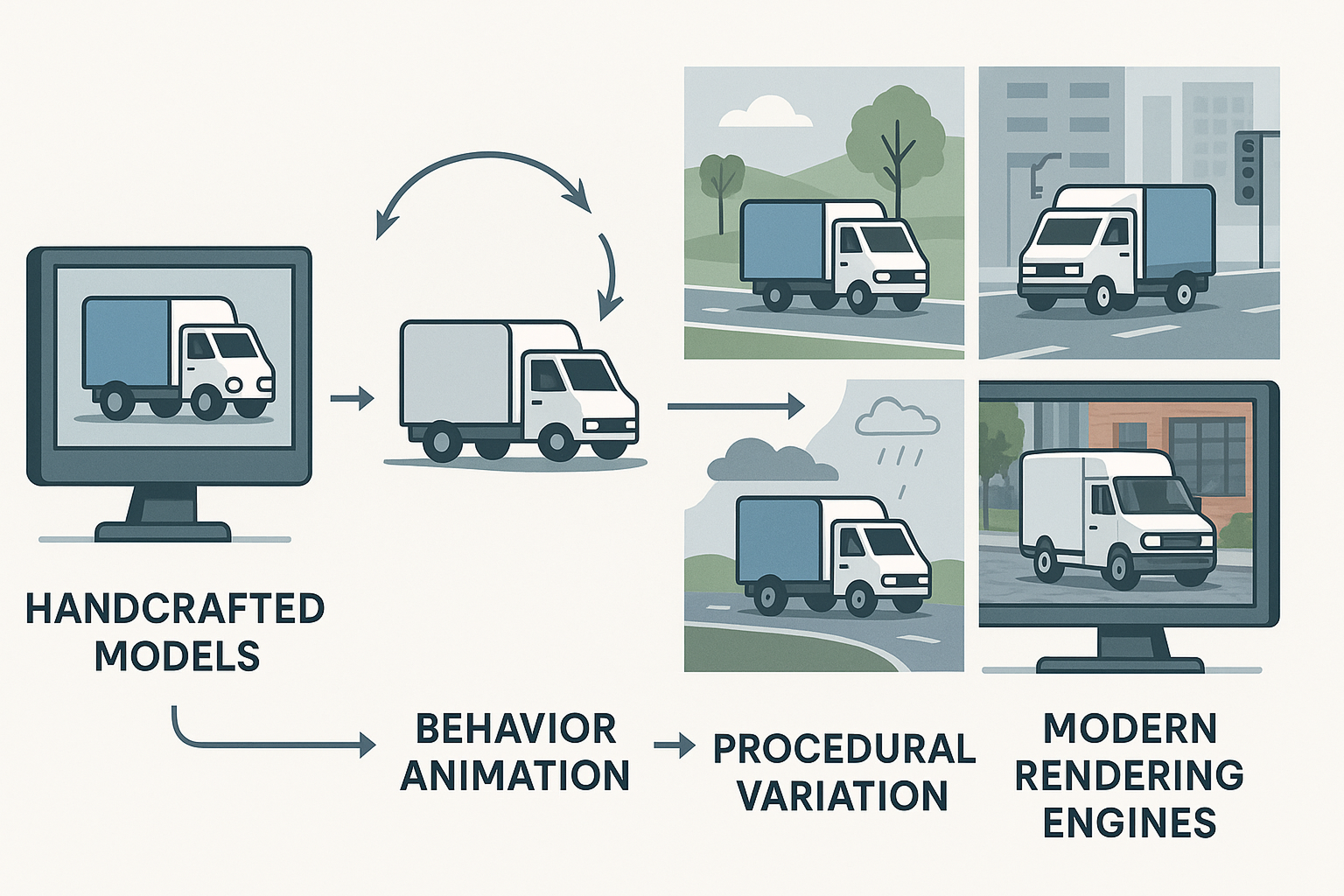
Synetic AI unites physically accurate assets, procedural scene generation, and automated annotation, delivering synthetic data that powers real-world AI performance.
Want to See It in Action?
Skip the guesswork and start creating production-ready synthetic data for computer vision. Describe what you need — we’ll generate, annotate, and validate it.
How Synthetic Data Is Generated for Computer Vision Model Training
Creating synthetic data for computer vision is both an art and a science. It can also be a way to outsmart nature or your data limits—without ever hassling an intern. The process involves making virtual scenes that reflect the real world. You have control over every pixel, shadow, and even that one apple that always seems to roll away.
Here’s how it works in a nutshell (or an apple crate, depending on your dataset):
- 3D Simulation & Rendering: Tools like Unreal and Unity build realistic scenes with objects, lighting, and motion. These simulations look like the real world. You can create anything from a sunny orchard to a midnight warehouse rave for your forklifts.
- Procedural Generation: Algorithmic rules generate endless combinations of object types, positions, backgrounds, and environmental factors. Want 10,000 apples with slightly different bruises? No problem—no orchard (or apple-picking interns) required.
- Generative AI: Models like GANs and diffusion networks can “hallucinate” entirely new images from scratch or remix real samples. These are perfect for adding extra realism, new textures, or a dash of digital chaos to your dataset—without summoning any fruit flies.
- Hybrid Approaches: These methods blend traditional 3D rendering with generative AI tools to boost visual realism or expand diversity. Historically, this was useful when synthetic rendering alone couldn’t deliver sufficient detail or realism. But as simulation and procedural generation technologies advance, the need for post-processing enhancements is beginning to diminish. Today’s synthetic pipelines can often achieve photorealism and control directly, making many hybrid approaches less necessary (and freeing up your weekends).
At Synetic AI, we blend physically accurate simulation, procedural scene generation, and a layer of human validation for quality. This means your dataset comes with pixel-perfect annotations, bounding boxes, segmentation, depth, keypoints, and more—without ever hassling an intern.
If only growing apples (or finding forklifts at midnight warehouse raves) was this consistent.
The result? Controlled variation at massive scale, instant annotation, and a dataset that never complains about overtime (or requests a coffee break). Synthetic data generation lets you skip the slow, manual collection grind, delivering consistency, speed, and coverage that would make any orchard jealous.
Industry Use Cases for Synthetic Data in Computer Vision
Synthetic datasets are transforming computer vision across industries. Here are just a few of the ways simulation-based data is already delivering real-world results:
Agriculture
Synthetic imagery helps detect crop growth, weed problems, and disease early—without waiting for these issues to physically appear in the field. Simulated data accounts for different soil types, lighting, weather, and crop stages, enabling robust detection systems.
Livestock & Animal Health
Stall-mounted cameras monitor horses or cattle for abnormal behaviors like prolonged lying, pacing, or limping. These events are rare in real life. Synthetic datasets generate thousands of examples under different poses, lighting, and angles, helping enable earlier detection.
Manufacturing & Quality Inspection
Defect detection models need large volumes of labeled examples, but real defects are rare. Synthetic data simulates part misalignments, microcracks, scratches, and assembly errors under varied lighting and magnification. This leads to significantly broader coverage.
Warehouse Robotics
Robots navigating busy warehouse floors must recognize humans, pallets, boxes, and other robots in complex settings. Synthetic datasets simulate dynamic layouts, occlusions, motion blur, and lighting changes to improve collision avoidance and generalization.
Security & Surveillance
Training for loitering, perimeter breaches, or unusual motion is difficult due to privacy constraints and event rarity. Synthetic data offers a diverse set of behaviors and subjects, without depending on real incidents or violating privacy regulations.
Retail & Checkout Automation
Checkout systems need to detect items from different angles, often under occlusion or with partial barcode visibility. Simulated shopping environments allow fast iteration and training without recording real customers or relying on staged footage.
Infrastructure Inspection
From road cracks to bridge inspections, synthetic aerial and street-level datasets enable consistent model training, even for hard-to-capture or hazardous conditions like bad weather or remote access points.
Pre-Deployment Testing
Synthetic environments help validate computer vision systems before they’re deployed. Developers test performance under simulated fog, glare, snow, or vibration, catching problems early without field testing.
Public Benchmark Datasets for Synthetic Data in Computer Vision
- Synscapes: Photorealistic dataset for segmentation and object detection.
- Virtual KITTI 2: Synthetic clone of KITTI for benchmarking.
- CARLA: Open-source simulator for autonomous vehicle data.
- AirSim: Microsoft’s simulator for drones and self-driving vehicles.
- BlenderProc: Scene generation and annotation using Blender.
- Falling Things (FAT): Dataset for 6D object pose in cluttered scenes.
- Synthehicle: Stylized vehicle detection and localization.
- SceneNet RGB-D: Indoor scenes with depth annotations.
- Hugging Face: Synthetic datasets and generative model zoo.
Real-World vs. Synthetic Data: Which Is Better for Training Computer Vision AI Models?
Historically, real-world images were the default choice for computer vision training, despite being expensive and limited. But synthetic data has matured. Now it offers equal or superior results in many domains.
Synthetic data provides perfect annotations, full environmental control, and the ability to generate rare or dangerous scenarios on demand. It enables engineers to build balanced, comprehensive datasets that real data often cannot match.
While some teams still mix synthetic and real data in hybrid pipelines, this practice was born from a time when synthetic realism and diversity weren’t sufficient. As those limitations fade, the need for hybrid pipelines will likely diminish.
In short: when synthetic data is generated with physical realism, procedural variation, and domain relevance, it can match or exceed real data in model performance. And it does so faster, cheaper, and with fewer blind spots.
The Synetic AI Synthetic Data Process for Computer Vision
Synetic AI streamlines the journey from idea to deployable vision AI. Whether you’re building a model to detect defects on an assembly line, track livestock behavior, or identify rare plant species, our process adapts to your goals — without the bottlenecks of traditional data pipelines.
- Step 1: Describe What You Want to Recognize
Start with a natural language description; no technical specs required. Whether it’s “horses lying down in a stall” or “rock fragments smaller than 2 inches,” we convert your input into a structured dataset plan. - Step 2: Generate the Scene
Synetic AI builds a 3D environment that includes your object of interest in varied poses, lighting, materials, and environments. We simulate physics, camera sensors, and behavior to ensure realism. - Step 3: Create Variation at Scale
We generate thousands to millions of labeled images that cover lighting, angle, occlusion, background, object placement, and more. This step is fully procedural and supports depth maps, segmentation, keypoints, and behaviors. - Step 4: Train Your Model
Choose from popular architectures like YOLOv8, RT-DETR, or DINOv2, or bring your own. Training is handled by our platform with real-time monitoring and tunable parameters. - Step 5: Deploy or Export
Download the trained weights, the full dataset, or a ready-to-integrate SDK. Our wrappers include options for behavior detection, tracking, and edge device compatibility.
This streamlined pipeline lets teams go from concept to production-ready models in days instead of months.
How Do We Know Synthetic Data Works for Computer Vision Training?
The effectiveness of synthetic data is not just theoretical: it’s validated through rigorous testing. A key benchmark is generalization: the ability of a model trained on synthetic images to accurately identify objects in real-world conditions.
This reinforces how synthetic data for computer vision performs when applied to real-world conditions.
Models trained entirely on synthetic datasets have repeatedly matched or exceeded the accuracy of those trained on hand-labeled photographs. In scenarios where real-world data is limited, biased, or lacks edge cases, synthetic data often delivers superior performance.
Industry-wide A/B testing has demonstrated consistent results across sectors including agriculture, robotics, and manufacturing. When synthetic datasets are generated with physical realism and broad variation, they enable models to close the “reality gap” and achieve reliable real-world performance.
These highly accurate simulations allow models to train on edge cases without needing to wait for real-world incidents.
Synthetic data also enables new forms of evaluation. Algorithms can be tested in scenarios that would be too rare, dangerous, or expensive to capture physically, such as identifying a forklift during a sandstorm at night. Edge cases, failure conditions, and deployment constraints can all be simulated and validated in advance.
Generalization is the true test of a model’s effectiveness, and synthetic data passes.
Common Objections to Synthetic Data for Computer Vision: Why They Don’t Hold Up
Despite its growing adoption, synthetic data still faces skepticism in some circles. However, most objections are either outdated, based on policy inertia, or misunderstandings about how vision models work. Here’s a breakdown of common objections, and why they don’t hold up under scrutiny:
“Real data is required for compliance”
This is a regulatory artifact, not a technical necessity. Many compliance frameworks were written before synthetic data became viable. As synthetic datasets gain validation parity, policies will evolve. The issue here is policy lag, not performance.
“We trust real images more”
Trust should be based on objective performance, not intuition. Models care about statistical patterns, not whether a human photographer pressed the shutter. If synthetic data produces better generalization, that should be the benchmark, not familiarity bias.
“You can’t simulate what you don’t know”
True, but real data can’t either. If an edge case isn’t in your real dataset, it goes unlearned. Synthetic data actually allows teams to design and test for rare events intentionally, reducing blind spots instead of relying on luck.
“Synthetic data isn’t ground truth”
In some domains, like biomedical imaging or precise physical measurements, synthetic data may need to be validated against empirical benchmarks. But it still accelerates development and dramatically improves model readiness before any real measurements are collected.
“Marketing requires real photos”
Training and inference are different. A model trained on synthetic data can operate on real marketing images just fine. There’s no reason to gather manual training images just because the final use case is visually realistic.
“Real data helps you build the simulation”
Sometimes, teams collect real images to guide asset development, but this is a scaffolding step, not a justification for sticking with real data long-term. Once the simulation is built, synthetic pipelines are vastly more efficient and scalable.
“You still need to fine-tune on real data”
This used to be true. Today, most models trained with high-quality synthetic data work right away. Fine-tuning with real data is optional, not required.
In short, most objections to synthetic data are not grounded in technical limitations. They reflect a shift in mindset, tooling, and policy, and that shift is already well underway.
Most objections are mindset, not math.
What Comes Next for Synthetic Data in Computer Vision?
The role of synthetic data is rapidly expanding beyond object detection and classification. As AI systems take on increasingly complex tasks, including reasoning, temporal understanding, and multimodal perception, the need for rich, controllable training data is only growing.
Synthetic data is uniquely positioned to support the next wave of innovation in:
- Multimodal Learning: Combining images, text, audio, and other signals into unified models that can reason across input types.
- Foundation Models: Training large-scale vision-language models using structured, richly varied, and fully labeled synthetic corpora.
- Autonomous Systems: Validating performance under unpredictable edge cases and deployment conditions, from fog to falling debris, before any sensor hits the field.
- Digital Twins: Generating synthetic representations of entire environments or systems for forecasting, operations, and simulation-based decision making.
- Synthetic Humans: Enabling AI to learn from a wide diversity of human forms, behaviors, and social interactions to support accessibility, safety, and inclusion.
As simulation pipelines become more sophisticated, the line between “real” and “synthetic” continues to blur, not just visually, but in how machines learn. The future of vision isn’t just about seeing the world. It’s about simulating what could be, and building models that thrive in the unpredictable.
Ready to Get Started?
Whether you’re building your first model or scaling your vision AI across industries, Synetic AI is here to help. Let us know what you want to recognize, and we’ll generate everything you need to train, validate, and deploy.
Frequently Asked Questions
Can synthetic data fully replace real data?
Yes, and in many cases, it should. Synthetic data pipelines today offer control, coverage, and label quality that real-world datasets can’t easily match. In edge-heavy environments or when rapid iteration is required, synthetic approaches often outperform traditional methods.
Real data may still assist in benchmarking or tuning, but it is no longer required to train production-quality models.
Do I need a simulation team?
No. Older platforms required deep simulation expertise or dedicated 3D teams. That’s no longer necessary. Newer platforms abstract the technical work, allowing teams to generate and annotate data from natural-language prompts, without handling 3D assets or scene configuration manually.
What models can I train with synthetic data?
Nearly all major architectures, including YOLOv8, RT-DETR, DINOv2, and custom backbones, can be trained using synthetic data. Many platforms allow exporting datasets or integrating directly with training pipelines.
Do I need 3D modeling experience?
No. Many synthetic data platforms handle the 3D modeling, animation, lighting, rendering, and annotation automatically. You can describe what you want and receive a labeled dataset, without ever opening a modeling tool.
Looking for high-quality, low-cost synthetic data for training your computer vision models? Synetic.ai delivers datasets faster, with better annotation and no need for real-world image collection.Synthetic data is revolutionizing computer vision. Synetic.ai provides an automated platform for generating training datasets that are photorealistic, annotated, and customizable.