

The Synetic difference

No-gen synthetic image

Real-world generalized image
The old way: real-world data
Every vision system today has been trained the same way: collect real images, label them by hand, and hope there’s enough coverage to generalize.
But this approach is fundamentally broken.
Computer vision has been bottlenecked by these limitations for decades.
The shift: rendered data
Synetic AI turns data collection into data design. Instead of waiting for the real world to give you examples, you generate them, perfectly controlled, infinitely repeatable.

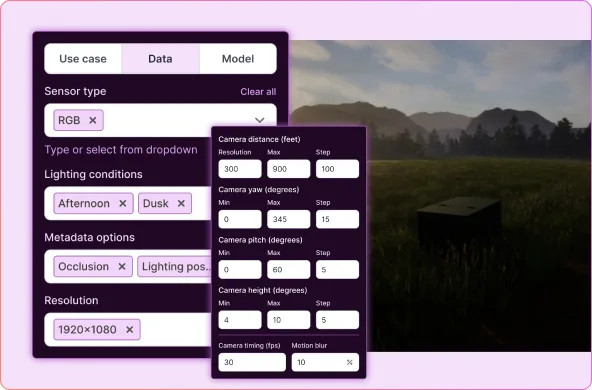

The proof
This isn’t marketing hype, it’s peer-reviewed science. In collaboration with the University of South Carolina, Synetic AI datasets were tested head-to-head against real-world data on industry benchmarks. The result: 33% higher accuracy. That means models trained on Synetic data didn’t just match real data. They beat it.
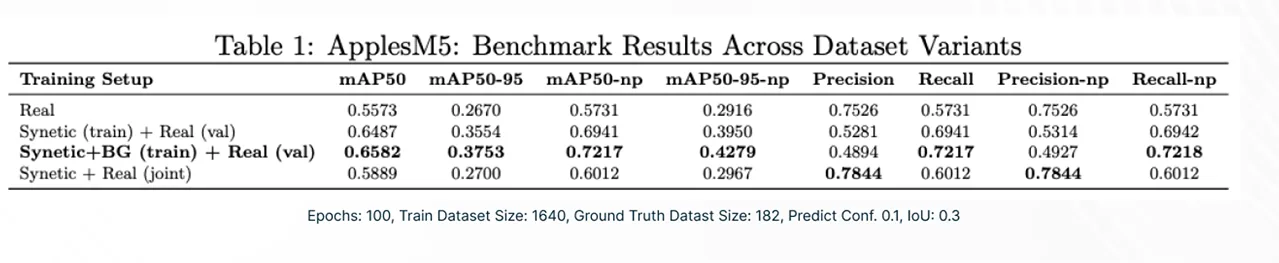
The payoff
Rendered data doesn’t just replace real-world data — it outperforms it.
Better
Train models that generalize more effectively to real-world conditions.
Faster
Skip months of collection and labeling. Generate datasets on demand.
More efficient
Eliminate annotation costs and wasted collection cycles.
The future
The shift is inevitable. Computer vision won’t be built on the limitations of reality anymore.
It will be built on precision-engineered data, designed, tested, and deployed at scale.
Synetic isn’t just keeping up with that future. We’re creating it.
Stop annotating. Start generalizing
Your contact info