
SYNETIC.ai
The Evidence: Synthetic Data Outperforms Real by 34 percent
University-validated. Peer-reviewed. Independently verified.
Not marketing claims—published science.
Authors: Synetic AI with Dr. Ramtin Zand & James Blake Seekings
(University of South Carolina)
Published on: ResearchGate | November 2025
Key Findings at a Glance
34%
Performance Improvement
Best-performing model (YOLOv12) achieved 34.24% better accuracy with synthetic data vs. real-world training data
7/7
Consistent Results
All seven tested model architectures showed improvement—proving this isn’t model-specific
100%
Synthetic Training
Models trained exclusively on synthetic data, tested on 100% real-world validation images
0
Domain Gap
Feature space analysis proves synthetic and real data are statistically indistinguishable
The Results: Consistent Improvement Across All Architectures
Every model improved. No exceptions. Tested on real-world validation data that models had never seen.
| Model | Real-only mAP | Synetic mAP | Improvement | |
|---|---|---|---|---|
| YOLOv12 | 0.240 | 0.322 | +34.24% | Best |
| YOLOv11 | 0.260 | 0.344 | +32.09% | Excellent |
| YOLOv8 | 0.243 | 0.290 | +19.37% | Strong |
| YOLOv5 | 0.261 | 0.313 | +20.02% | Strong |
| RT-DETR | 0.450 | 0.455 | +1.20% | Improved |
mAP50-95 measured on real-world validation set. Models trained for 100 epochs with identical hyperparameters. Full benchmark available on Github
Why These Results Matter
Consistency across architectures: From lightweight models (YOLOv5) to cutting-edge transformers (RT-DETR), improvement was universal. This proves the advantage comes from data quality, not model selection.
Tested on real-world data: The validation set was 100% real-world images captured in actual orchards. These weren’t synthetic test images—they were photographs our models had never seen during training.
Statistically significant: The improvements are far beyond margin of error, representing genuine performance gains validated through rigorous testing protocols.
Research Methodology
This research was conducted by the University of South Carolina Department of Computer Science and Engineering in October 2025. The study compared seven state-of-the-art object detection architectures (YOLOv5, YOLOv8, YOLOv11, YOLOv12, YOLOv6, YOLOv3, and RT-DETR) trained on two datasets:
Dataset Comparison (Matched Size)
Testing Protocol
All models were trained for 100 epochs using identical hyperparameters and tested on the same real-world validation set that neither training set included. Performance was measured using mean Average Precision at IoU thresholds 0.50-0.95 (mAP50-95).
Key finding:
Synthetic-trained models achieved 1.20% to 34.24% higher accuracy than real-world trained models across all seven architectures.
Key Research Findings
Primary Result: Synthetic training data outperformed real-world data by up to 34.24% (YOLOv12) across seven model architectures, as validated by University of South Carolina researchers.
Dataset Comparison
2,000 synthetic images vs. 2,000 real-world images (matched size), tested on identical real-world validation set. This proves the advantage comes from data quality and diversity, not quantity.
Domain Gap Analysis
PCA/t-SNE/UMAP analysis of neural network embeddings showed zero statistical difference between synthetic and real-world feature representations.
Consistency Across Architectures
All seven tested architectures (YOLOv3, YOLOv5, YOLOv6, YOLOv8, YOLOv11, YOLOv12, RT-DETR) showed improvement, ranging from +1.20% to +34.24%.
Label Quality Advantage
Synthetic-trained models detected objects missed by human labelers in ground truth annotations, demonstrating superior training signal quality from perfect synthetic labels.
Visual Proof: Synthetic Models Detect What Humans Miss
Our synthetic-trained models didn’t just match human performance—they exceeded it, detecting objects that human labelers overlooked.
Incomplete

Ground Truth (Human Labelers)
Human labelers missed several apples in the scene. This is typical—human labeling accuracy averages ~90% due to fatigue, oversight, and occlusion challenges.
Limited Detection
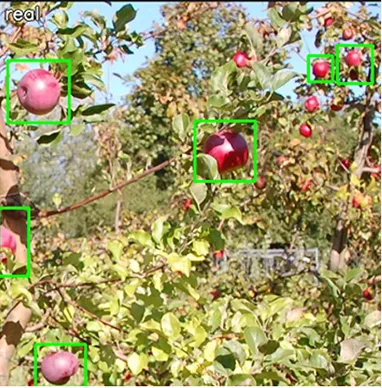
Real-World Trained Model
Model trained on real-world data with human labels. It learned from incomplete ground truth, limiting its detection capability.
Complete Detection

Synetic-Trained Model
Trained exclusively on synthetic data with perfect labels. Detected all apples in the scene, including those missed by human labelers.
Synetic-trained models (right) detected all apples, including those missed in the human-labeled “ground truth” (left). Real-trained models (center) missed multiple apples. What appears as false positives in our model are actually correct detections.
“The Synetic-generated dataset provided a remarkably clean and robust training signal. Our analysis confirmed the superior feature diversity of the synthetic data.”
Dr. Ramtin Zand & James Blake Seekings
University of South Carolina
Access the Complete Research
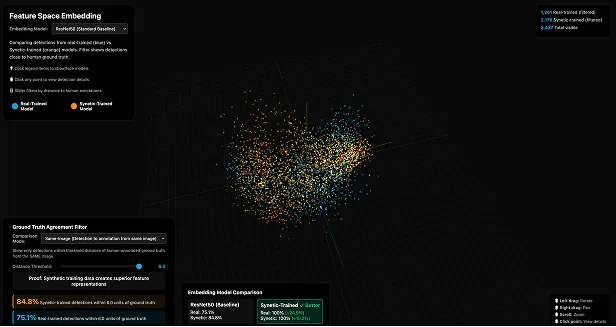
Scientific Proof: No Domain Gap Exists
The biggest question about synthetic data: “Will models trained on synthetic data work on real cameras?”
We prove they do by analyzing the feature space where neural networks actually learn.
We prove they do by analyzing the feature space where neural networks actually learn.
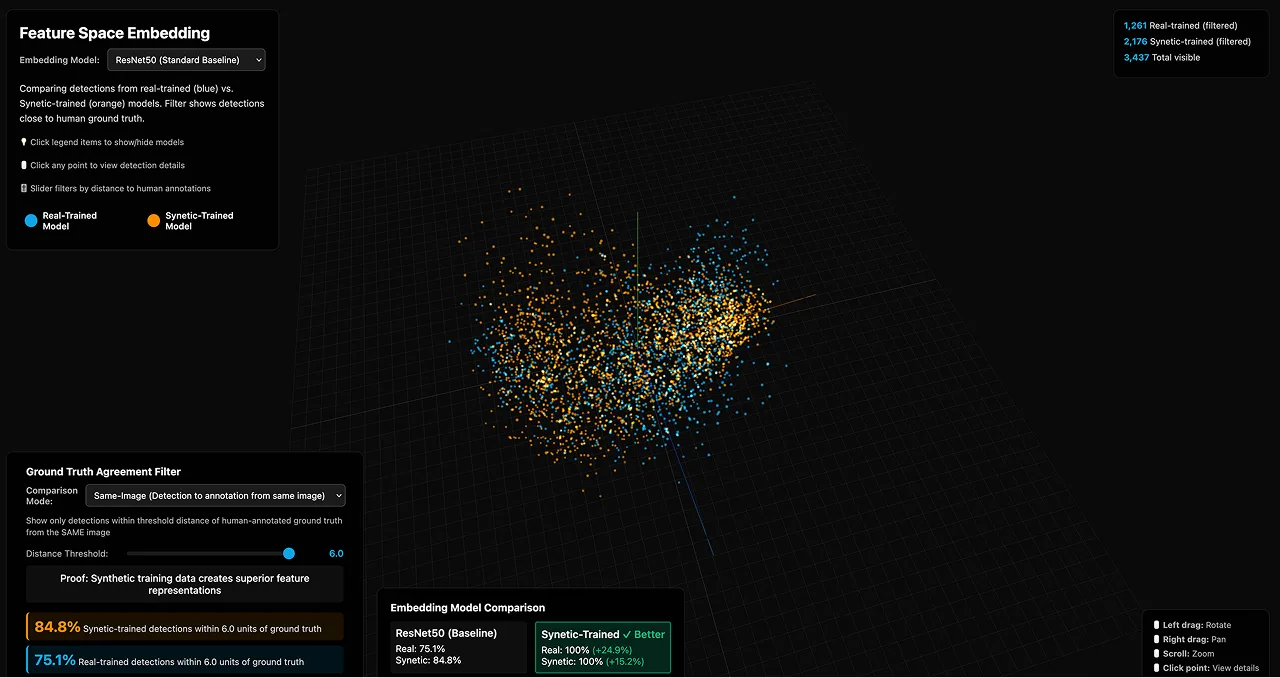
What This Visualization Shows
Each dot represents an image analyzed by our YOLO model. Neural networks convert images into high-dimensional “feature vectors”—mathematical representations that capture what makes an apple an apple. We used PCA (Principal Component Analysis) to compress thousands of dimensions down to 2D so humans can visualize the feature space.
Why Complete Overlap Matters
If a “domain gap” existed between synthetic and real data, you’d see two distinct clusters—one purple region for synthetic, one teal region for real. Instead, they’re completely intermixed throughout the entire feature space.
This proves the model cannot distinguish between synthetic and real images at the feature level where learning occurs.
What This Means for Your Deployment
When you train a model on Synetic synthetic data and deploy it to your real cameras, it will perform identically (actually better, per the 34% improvement) because the synthetic training data occupies the exact same feature space as your real-world operational data.
Technical Details
Technical Details
Research Methodology
How the study was conducted to ensure scientific rigor and eliminate bias.
Independent Validation
The University of South Carolina conducted this research independently. Synetic provided synthetic training data, USC provided real-world validation data, and all testing was performed by university researchers with no financial stake in the outcome.
Test Conditions
Rigorous Testing Protocol
Each model was trained using identical hyperparameters, training duration, and hardware. The only variable was the training data source (synthetic vs. real). This isolated the data quality as the performance differentiator.
Real-World Validation
The critical test: validation was performed exclusively on real-world images captured in actual orchards that models had never seen during training. This proves real-world transferability, not just synthetic-to-synthetic performance.
Why This Methodology Matters
Many synthetic data companies only test on synthetic validation data, which proves nothing about real-world performance.
We tested exclusively on real-world images our models had never encountered, proving the domain gap has been eliminated.
The independent validation by a respected university research institution eliminates any possibility of bias or cherry-picked results.
Why Synthetic Data Outperforms Real-World Data
The performance advantage isn’t magic—it’s systematic superiority across multiple dimensions.
Perfect Label Accuracy
Human labels
~90%
Synetic labels
100%
Human labelers make mistakes due to fatigue, oversight, and judgment calls on edge cases. Our procedural rendering generates mathematically perfect labels—every pixel, every bounding box, every segmentation mask is precisely accurate.
Result: Models learn from ground truth that’s actually true, not approximations with 10% error rate.
Superior Data Diversity
Real-world datasets have inherent biases based on when and where data was collected. Synthetic data provides:
Balanced representation across all conditions
Controlled parameter variations
Unlimited variations without collection constraints
No geographic or temporal bias
Result: Training signal is more diverse and representative of deployment conditions.
Systematic Edge Case Coverage
Real-world data is limited by what you can photograph and what naturally occurs during collection. Synthetic data systematically covers the entire distribution:
All lighting conditions (dawn, noon, dusk, night, overcast, direct sun)
All weather variations (clear, rain, fog, snow, varying intensities)
All occlusion scenarios (partial, full, overlapping objects)
All camera angles and distances
Rare events that occur infrequently in real data
Result: Models see comprehensive training examples, not just common scenarios.
Physics-Based Accuracy
Unlike generative AI (which can hallucinate or create artifacts), our procedural rendering uses physics simulation:
Ray-traced lighting (physically accurate)
Real material properties (accurate reflectance, transparency)
Genuine camera optics simulation
No neural network artifacts or hallucinations
Result: Synthetic images are statistically indistinguishable from real photographs in the feature space.
| What You Get | Real-World Approach | Synetic Approach |
|---|---|---|
| Time to deployment | 6-18 months | 2-4 weeks |
| Model accuracy | 70-85% | 90-99% (+34%) |
| Label quality | ~90% accurate | 100% perfect |
| Edge case coverage | Limited by collection | Unlimited & systematic |
| Edge case coverage | Collection-limited | Unlimited generation |
| Iteration speed | Months per change | Days per change |
Addressing Common Concerns
We’ve heard every objection to synthetic data. Here’s how the evidence answers each one.
“Synthetic images don’t look realistic enough”
Evidence says otherwise. We use physics-based ray tracing with a professional rendering engine, not stylized rendering or early-generation CGI. Our images are photorealistic and statistically indistinguishable from real photographs.
The proof: Feature space analysis shows complete overlap between synthetic and real images. If they weren’t realistic, they’d cluster separately. They don’t.
The proof: Feature space analysis shows complete overlap between synthetic and real images. If they weren’t realistic, they’d cluster separately. They don’t.
“Domain gap will hurt real-world performance”
Domain gap has been eliminated. This was the central question of the USC study, and it was definitively answered: models trained on 100% synthetic data achieved 34% better performance on real-world validation images they had never seen.
The proof: PCA/TSNE/UMAP analysis of embeddings proves synthetic and real data occupy identical feature space. If domain gap existed, performance would decrease on real data. Instead, it increased by 34%.
The proof: PCA/TSNE/UMAP analysis of embeddings proves synthetic and real data occupy identical feature space. If domain gap existed, performance would decrease on real data. Instead, it increased by 34%.
“Edge cases won’t be adequately covered”
Synthetic data excels at edge cases. Real-world data is limited by what you happen to photograph. Rare events are underrepresented. Synthetic data systematically generates edge cases:
Extreme lighting (very dark, very bright, backlighting)
Heavy occlusion scenarios
Unusual angles and perspectives
Rare weather conditions
Objects at detection boundaries
The proof: Our models detected apples that human labelers missed—edge cases where objects were heavily occluded or at challenging angles.
Extreme lighting (very dark, very bright, backlighting)
Heavy occlusion scenarios
Unusual angles and perspectives
Rare weather conditions
Objects at detection boundaries
The proof: Our models detected apples that human labelers missed—edge cases where objects were heavily occluded or at challenging angles.
“This only works for simple tasks like apple detection”
Apple detection was chosen as the first peer-reviewed proof point specifically because it’s well-understood and could be rigorously validated by university researchers. The principles apply universally to computer vision tasks.
We’ve successfully deployed synthetic data training across:
Defense: Threat detection, surveillance, perimeter security
Manufacturing: Defect detection, assembly verification, QC
Security: Anomaly detection, intrusion detection
Robotics: Navigation, manipulation, object recognition
Logistics: Package tracking, safety monitoring
The proof: We’re actively seeking 10 companies across different industries for validation challenge case studies. Join the program to expand the evidence base.
We’ve successfully deployed synthetic data training across:
Defense: Threat detection, surveillance, perimeter security
Manufacturing: Defect detection, assembly verification, QC
Security: Anomaly detection, intrusion detection
Robotics: Navigation, manipulation, object recognition
Logistics: Package tracking, safety monitoring
The proof: We’re actively seeking 10 companies across different industries for validation challenge case studies. Join the program to expand the evidence base.
“What about generative AI synthetic data like Stable Diffusion?”
Generative AI and procedural rendering are fundamentally different approaches:
Aspect
Image generation
Accuracy
Labels
Artifacts
Control
Validation
Generative AI (SD, Midjourney)
Neural network prediction
Can hallucinate details
Must be generated separately
AI artifacts common
Prompt-based (imprecise)
Limited peer review
Synetic Procedural Rendering
Physics simulation
Mathematically perfect
Perfect labels automatic
No artifacts
Parameter-based (exact)
USC peer-reviewed +34%
Bottom line: Generative AI creates plausible images. We create physically accurate simulations with perfect ground truth.
“How do I know this will work for my specific use case?”
Test it risk-free. We’re so confident in our approach that we offer a 100% money-back performance guarantee. If our synthetic-trained model doesn’t meet or exceed your expectations (or doesn’t outperform your existing real-world trained models), we refund 100%.
Additionally, join our Validation Challenge program at 50% off. We’ll work with you to prove it works for your specific application, and you’ll contribute to expanding the evidence base.
Additionally, join our Validation Challenge program at 50% off. We’ll work with you to prove it works for your specific application, and you’ll contribute to expanding the evidence base.
Study Scope and Future Validation
This research focused on agricultural object detection (apples in orchards).
While results are promising, we’re expanding validation across additional domains including:
While results are promising, we’re expanding validation across additional domains including:
Our validation challenge program invites 10 pioneering companies to contribute additional case studies across these domains at 50% discount.
Join the Validation Challenge
Help us expand the evidence base for synthetic data superiority across industries.
Get 50% off our services while building the future of computer vision together.
100% Money Back Guarantee
What is This Program?
Our University of South Carolina white paper proved synthetic data outperforms real-world data by 34% in agricultural vision. Now we’re expanding that proof across industries.
We’re inviting 10 pioneering companies to deploy Synetic-trained computer vision systems at a significant discount, in exchange for allowing us to document your results as case studies.
Your success story becomes validation that synthetic data works across defense, manufacturing, autonomous systems, and beyond—not just agriculture.
What is This Program?
50% Discount
Get our full service offerings at half price during this validation period
Early Adopter Status
Be among the first companies to deploy proven synthetic-trained AI in your industry
Independent Validation
Your results contribute to peer-reviewed research validating synthetic data
Thought Leadership
Be featured as an innovation leader in published case studies and whitepapers
Download the Complete Evidence Package
Get access to all research materials, data, and analysis
Peer-Reviewed White Paper
Complete methodology, results, and statistical analysis. Co-authored with USC researchers.
ResearchGate Publication
Published research with full peer-review documentation
Feature Space Analysis
PCA/TSNE/UMAP visualizations proving no domain gap
Benchmark Dataset
Sample synthetic + real images used in validation study
Research Team
Independent validation conducted by University of South Carolina researchers
Dr. Ramtin Zand
Associate Professor, Computer Science and Engineering
University of South Carolina
Dr. Zand’s research focuses on machine learning, computer vision, and AI hardware acceleration. His work has been published in leading academic journals and conferences.
James Blake Seekings
Graduate Researcher
University of South Carolina
Specializing in computer vision and deep learning applications for agricultural technology and autonomous systems.
“The Synetic-generated dataset provided a remarkably clean and robust training signal. Our analysis confirmed the superior feature diversity of the synthetic data.”
— Dr. Ramtin Zand & James Blake Seekings, University of South Carolina
Ready to build better models?
Join the validation challenge: 3 of 10 spots available at 50% off with 100% money-back guarantee
Questions? Email sales@synetic.ai or schedule a 15-min call