
SYNETIC.ai
Peer-Reviewed and University-Verified
Co-authored with the University of South Carolina
Synetic AI partnered with faculty at the University of South Carolina to rigorously evaluate synthetic training data across seven top computer vision models, including YOLOv8, YOLOv11, YOLOv12, and RT-DETR.
The results?
Models trained exclusively on Synetic-generated datasets outperformed real-world annotated data by up to +34% in mAP@50-95, with even stronger improvements in model generalization and detection accuracy on unseen validation sets.
This peer-reviewed benchmark marks the first time fully synthetic data has been scientifically proven to outperform real data in rigorous academic testing.
Below is a sample from our benchmark results:
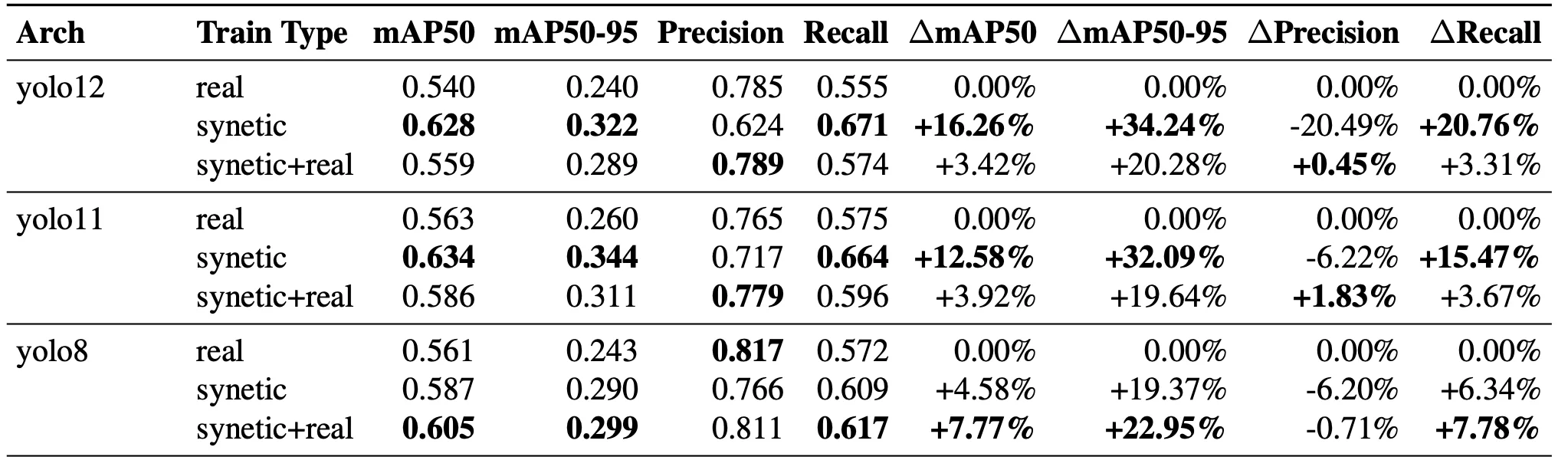
Epochs: 100, Train Dataset Size: 1640, Ground Truth Dataset Size: 182, Predict Conf: 0.1, IoU: 0.3
Download the full whitepaper, including:
- RT-DETR and other architecture results
- performance of mixed real + synthetic datasets
- evaluation metrics for real-world generalization
Synthetic data isn’t just catching up, it’s now the on track to become the Gold Standard to scalable, accurate AI model training.


Breakthrough Proof: Synthetic Data Outperforms Real Data
Backed by benchmark results, this research proves that synthetic data, when validated properly, can generalize better than real data alone. With up to 11% gains in detection accuracy, it’s a game-changer for anyone working in AI, automation, or visual recognition.